


The research industry is buying a lot of AI tools right now. Fraud detection, synthetic sample, automated QA, AI-generated analysis. Most of them come with numbers attached — accuracy rates, detection benchmarks, quality scores. Almost none of those numbers come from independent evaluation. They're self-published, self-attested figures from the vendors selling the tools. Which means the bar for "proven" is basically a company saying so.
That's not a knock on the vendors. It's a structural problem. Evaluating AI output is hard, and most research teams don't have a framework for doing it systematically. So they run a pilot, it looks reasonable, and it gets deployed. Then something breaks in production and nobody quite knows why.
There's a better way. And it turns out research operations is one of the best possible places to apply it.
Most ResOps workflows are deterministic. You know what a correctly programmed survey looks like. You know what a clean data file looks like. You know what a passed link test looks like. That clarity is rare in AI applications. Most of the time, evaluating AI means scoring something subjective — is this summary good? is this copy compelling? Those are genuinely hard questions to answer consistently. ResOps tasks mostly aren't. Either the skip logic routes correctly or it doesn't. Either the quota is enforced or it isn't. That gives you something concrete to test against, which is exactly what good evaluation requires.
Research from Stanford's Center for Research on Foundation Models has emphasized that systematic, transparent evaluation practices are essential for production AI deployments, and that ad-hoc testing is insufficient. ResOps, more than almost any other domain in research, has the structure to do this properly.
There are three distinct frameworks for testing AI systems. Each has different origins, applies to different problems, and asks a different fundamental question.
LLM-as-a-Judge: Automated Quality Evaluation
LLM-as-a-Judge is a technique where a large language model automatically evaluates the quality of outputs from other AI models. Instead of relying on human reviewers or simple metrics, you prompt a capable model with evaluation criteria and it assesses whether responses meet specified standards — essentially acting as a quality control inspector for other AI systems. The approach grew out of the natural language processing field's long struggle with evaluation. Traditional metrics could measure surface-level text similarity — how closely an AI's output matched a reference answer word for word — but couldn't capture whether a response was actually useful or correct.
Human evaluation, while accurate, is expensive, slow, and doesn't scale. Research shows that sophisticated judge models can align with human judgment up to 85%, which is actually higher than human-to-human agreement at 81%. By the time LLM-based products started shipping at scale, teams needed something that could evaluate thousands of outputs a day without a human reading each one. LLM judges filled that gap and are now standard practice in AI development teams building production applications.
This kind of testing works best for transformation tasks — where the input and output are both well-defined and you can describe what correct looks like. You have a rubric. You want consistent scoring at scale. The task repeats. AI survey programming is the canonical research example: given a questionnaire spec, did the AI produce a survey that correctly implements the intent? There are multiple correct implementations, so the judge evaluates functional equivalence rather than exact match, which is where rubric design gets interesting and where the accumulated expertise of experienced programmers becomes genuinely useful calibration data.
In practice, you define what good output looks like across the dimensions that matter — logic accuracy, routing completeness, edge case handling. You calibrate the judge against a set of outputs you already trust. Then you run every AI output through the judge automatically before it reaches a human reviewer. (This is exactly how Questra's free scorecard works — upload your questionnaire and finished export, and an AI judge scores the result across five dimensions.) As IBM researcher Pin-Yu Chen puts it: "You should use LLM-as-a-judge to improve your judgment, not replace your judgment." The judge flags. Humans decide.
Red Teaming: Adversarial Testing for Fraud Detection
Red teaming means actively trying to defeat the system you're evaluating. Instead of asking whether it produces good output under normal conditions, you build attacks, simulate adversaries, and look for the cracks. The goal is not to measure quality. It's to find failure modes before someone else does.
The concept originated in Cold War military simulations, where RAND Corporation ran exercises for the United States military with "red team" representing the Soviet Union and "blue team" representing the United States. In the 1990s, red teaming began to be adopted by private sector companies and government agencies for cybersecurity assessments, evolving alongside the growing sophistication of digital threats. The core idea has always been the same: if your own team can't beat your defenses, you have a reasonable basis for confidence. If they can, you've learned something important before an attacker does.
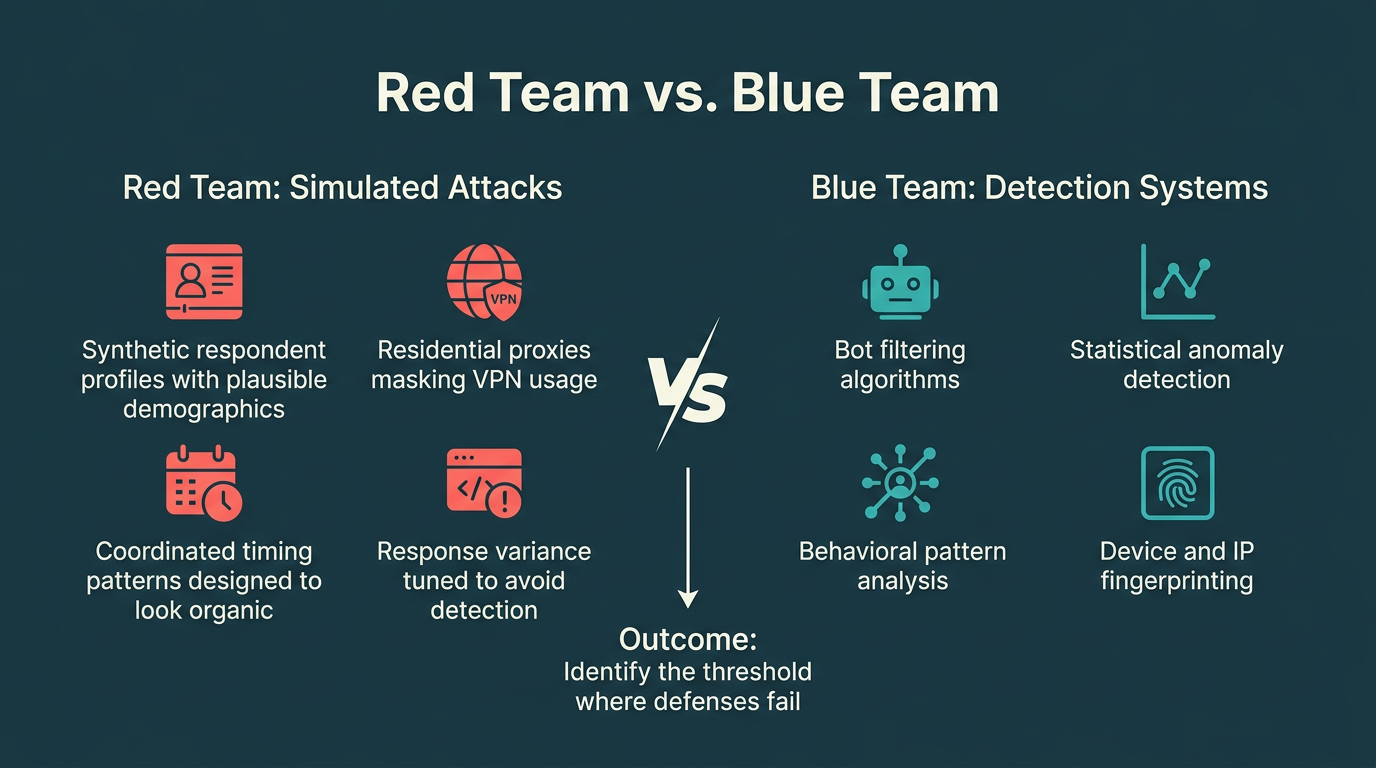
This is the right approach for any system that has an adversary — where motivated actors are actively trying to subvert the system's purpose. In research operations, that means fraud detection, bot filtering, and respondent verification. These are gatekeeping systems, and the only honest evaluation of a gatekeeping system is adversarial. The OP4G case made this concrete: a known bad actor operated undetected inside a respected vendor for years, passing ISO certification reviews, while fabricating data for major clients. It wasn't caught by the vendor's internal checks. It was caught by buyers. A serious red team exercise asks: could we have caught this ourselves? What would it take to defeat our own defenses?
In practice, a red team exercise against a fraud detection system means building realistic attacks. Synthetic respondent profiles with plausible demographic data. Residential proxies to mask VPN usage. Coordinated timing patterns designed to look organic. Response variance tuned to avoid statistical detection signatures. The goal isn't destruction — it's to find the threshold at which the system fails so you can raise it deliberately, before someone with worse intentions finds it first.
Regression Testing for AI-Powered Survey Tools
Regression testing asks a different question than the other two: not "is this output good?" and not "can this system be beaten?" — but "does this system still work the way it did before?" It's the discipline of verifying that a change to a system hasn't silently broken something it previously handled correctly.
The practice is foundational in software engineering, where shipping a new build without running a regression suite is considered reckless. The idea is straightforward: you maintain a set of known inputs with known expected outputs, you run every new version of your software against that suite, and you catch regressions before they reach production rather than after a user reports something broken.
In research operations, link testing is the perfect home for this approach. Link testing — the process of traversing every path through a survey to verify that routing, skip logic, piping, and quota enforcement all behave correctly — is inherently repetitive and rule-based. Every path either works or it doesn't. There's no subjectivity in whether a skip condition fires correctly. That makes it an ideal candidate for a regression suite.
The problem today is that link testing is almost entirely manual. When a survey gets revised, a tester clicks through the paths again. When the programming tool ships an update, someone re-tests the surveys. This is exactly the kind of exhausting, error-prone, time-consuming work that regression testing was invented to replace. A properly constructed regression suite for link testing means defining the complete set of paths through a survey as a versioned artifact, running every path automatically against every new build of the tool, and getting an immediate signal when something regresses. Instead of a tester spending hours re-clicking paths they've already walked a dozen times, the suite runs in minutes and flags the two paths that broke.
Most research teams are applying none of these approaches systematically. A few are beginning to use LLM judges in an ad hoc way. Almost none are red teaming their fraud and security tools. And regression suites for AI-powered link testing barely exist as a concept in the industry yet. The gap between teams that build real evaluation infrastructure and those that rely on vendor attestations is going to matter a lot more in the next 18 months than it has in the last 18. Getting ahead of that is one of the most important things a research operations function can do right now.
Questra automates survey programming and link testing — the operational steps that eat the most researcher hours and have the clearest quality benchmarks. Try the free scorecard to see how AI-generated surveys compare to yours, or sign up to start programming.